Input Block - Tokenization

In building LLMs, the first block is called input block. In this step, input text passed through the Tokenizer to create a tokenized text. This Token IDs are then passed through Embedding Layer and positional encoding is added before sending it to the transformer block.
I will talk about positional encoding later in the series. For now think of ids (numerical values) been sent to transformer block.
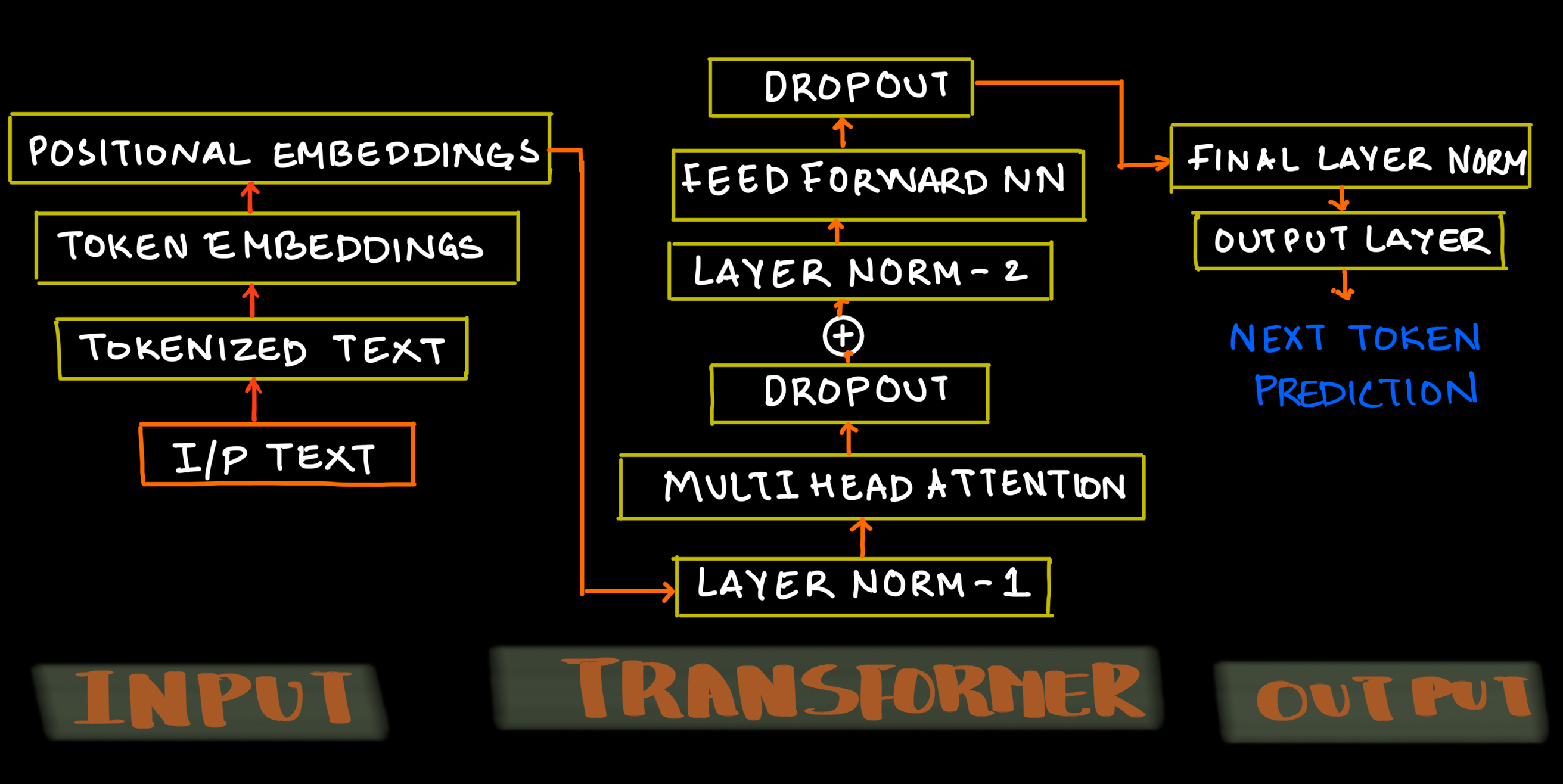
Here's the architecture of LLMs showing all three blocks.
Tokenizer
Input to the transformers are numbers not words, so we need to change the raw text to tokens (usually words, subwords or even characters) and convert it to token ids. This is called Tokenization.
The token ids are then passed to a neural network which transforms to continuous vector representations in a very high dimensional space. These dense vector representations capture semantic relationships between tokens, allowing machines to process language more effectively.
Here's how Embedding Matrix are typically created.
If you follow the text This - If token id is 2 , the embedding matrix could be [0.2, 0.8....]
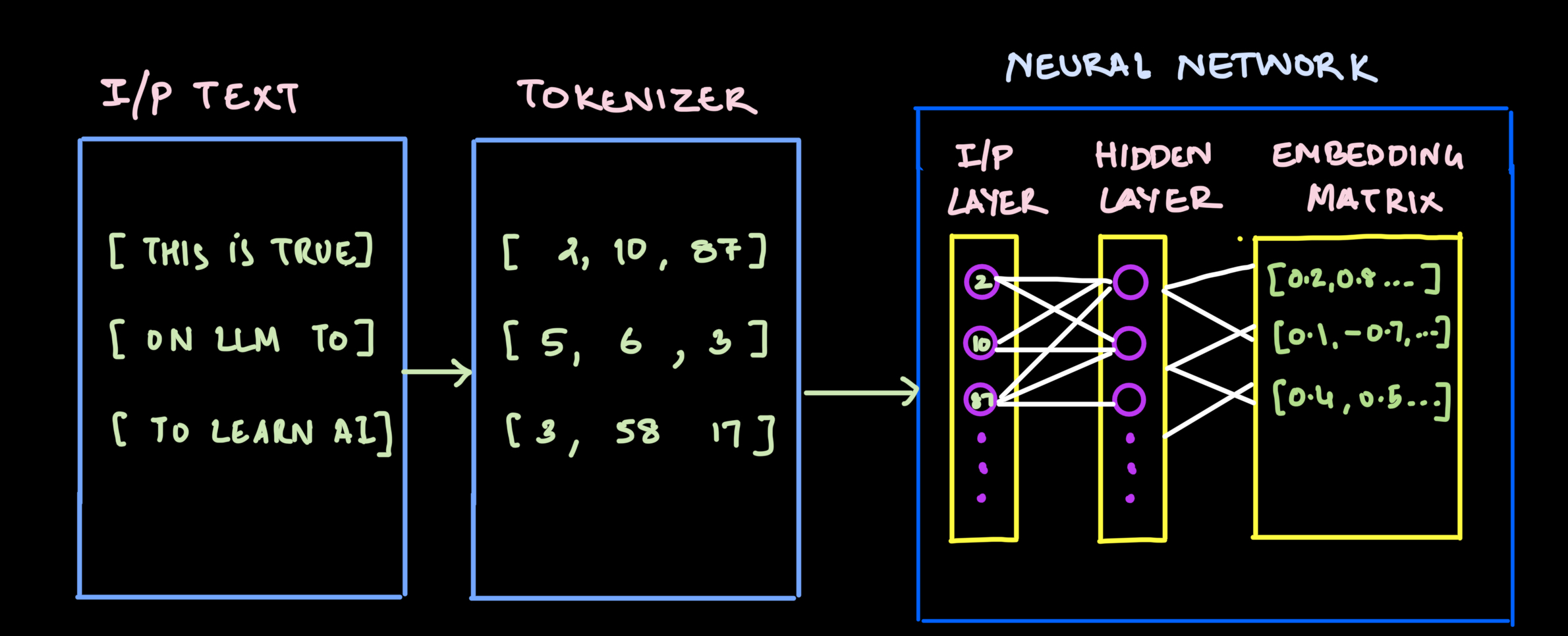
Embedding Matrix - A lookup table where each row corresponds to a specific token in the vocabulary and contains that token's learned vector representation.
Here's the summary -

Typically these Embedding size (rows) are between 768 to roughly 16K for each column inputs text.
Types of Tokenizer
To tokenize the input text, there are three types which are available. Sub-Word based tokenizers are what is typically used in LLMs.
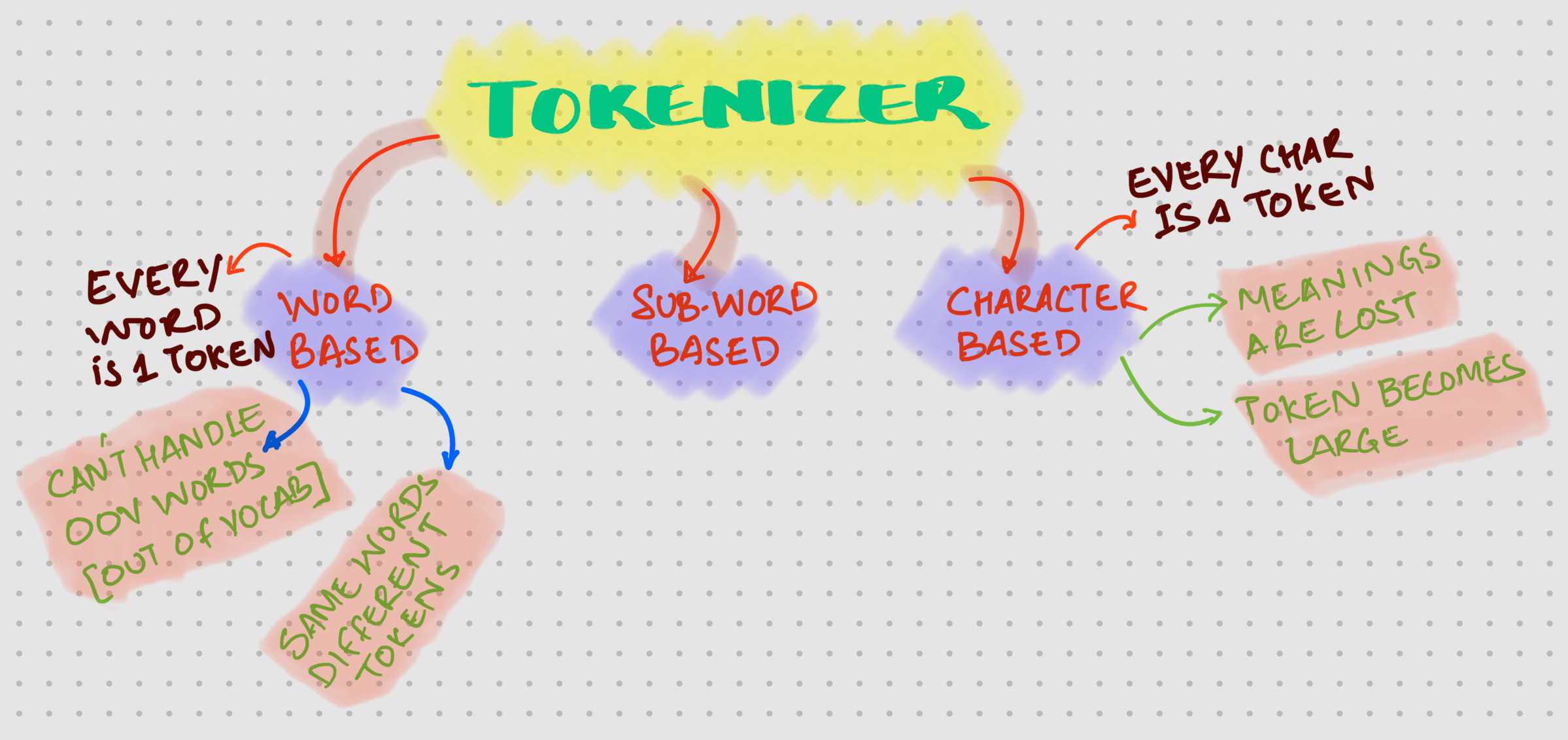
Byte Pair Encoding (BPE) is one such library.
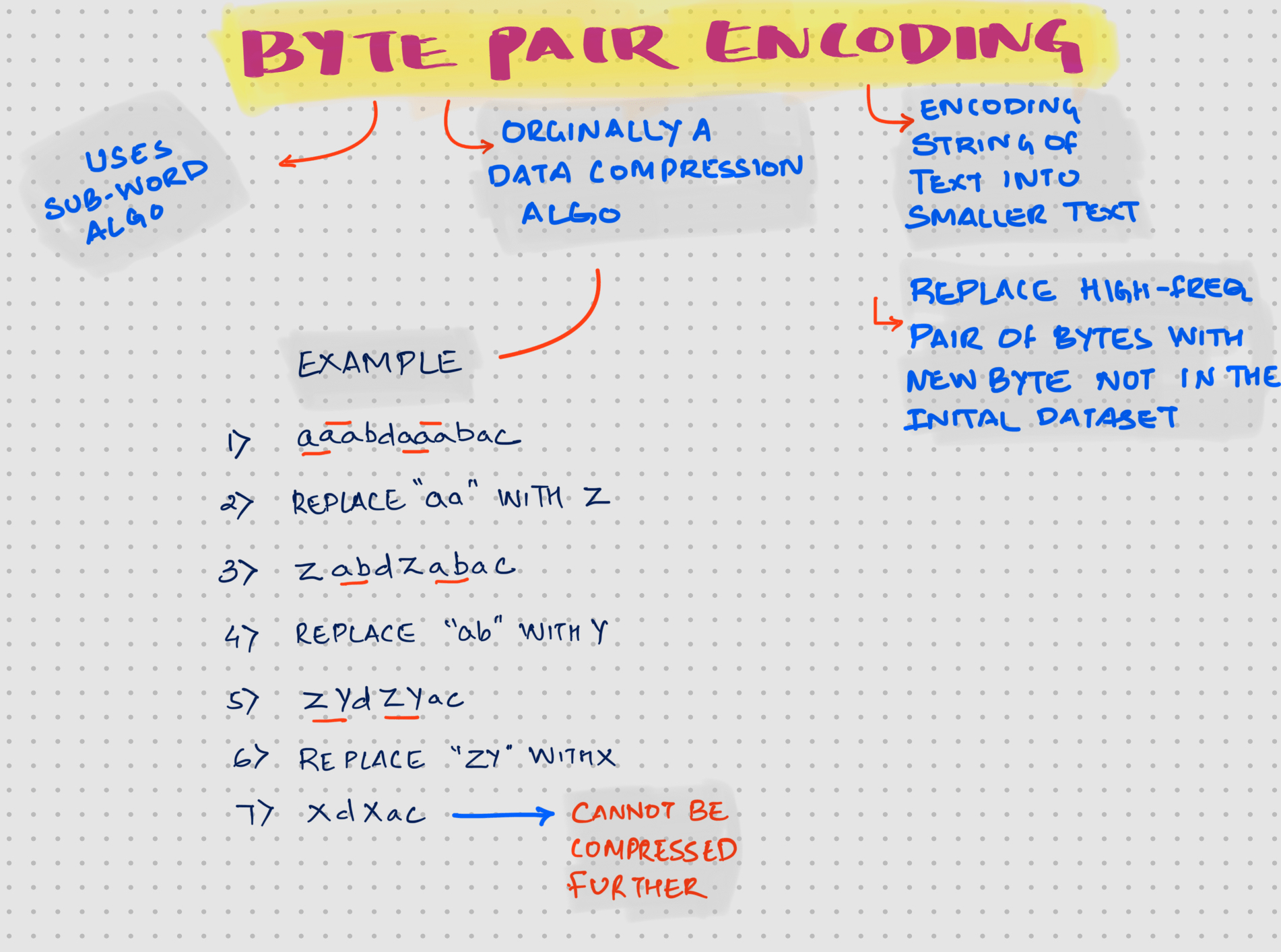
Byte Pair Encoding (BPE)
-
Orginally BPE was developed as a compression algorithm.
-
Checkout more details and the example used from Wiki
Modified BPE
In LLM, we use something called Modified Byte Pair Encoding. Used for encoding plain text to tokens

BPE Library
In Rust, you can use Tiktoken-rs for BPE
Equivalent Python library is available
Rust Code
Below is the rust code using Tiktoken-rs
use tiktoken_rs::o200k_base;
fn main() {
let bpe = o200k_base().unwrap();
let token: Vec<u32> = bpe.encode_with_special_tokens("This is multi line sentence for BPE with rust and a sentence with spaces");
println!("Token: {:?}", token);
println!("Decoding the token {:?}", bpe.decode(token));
}
Output of this program is as shown below
$> cargo run
## OUTPUT
#Token: [2500, 382, 12151, 2543, 21872, 395, 418, 3111, 483, 20294, 326, 261, 21872, 256, 483, 18608]
#Decoding the token Ok("This is multi line sentence for BPE with rust and a sentence with spaces")
Python Code
import tiktoken
tokenizer = tiktoken.get_encoding("o200k_base")
text_data = ( "Ecode using BPE via Python")
encoder_output = tokenizer.encode(text_data, allowed_special={"<|END|>"})
print(encoder_output)
decoder_output = tokenizer.decode(encoder_output)
print(decoder_output)
$> python3 bpe_example.py
## OUTPUT
# [36, 3056, 2360, 418, 3111, 4493, 26534]
# Ecode using BPE via Python